Evaluating Context Strategies for LLM Agents
Evaluating Context Strategies for LLM Agents
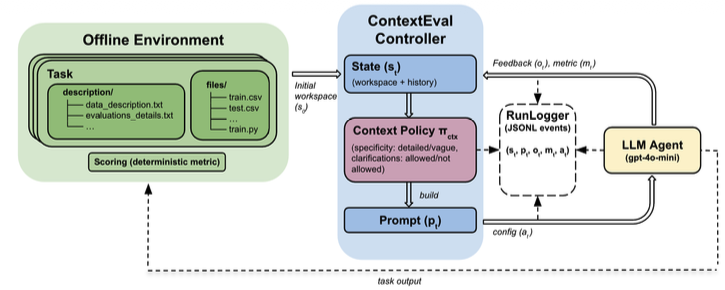
ContextEval investigates a core question in LLM agent evaluation: when an agent appears to improve at a task, is it demonstrating stronger reasoning, or is it simply benefiting from better access to information? The project focuses on LLM agents used for iterative machine learning experimentation, where the model proposes hyperparameter configurations, observes performance, and adjusts its next proposal. Rather than treating prompt content as a fixed design choice, ContextEval treats context visibility as an experimental variable that can be controlled, varied, and measured.
The research introduces a controlled framework for studying how different categories of information affect agent behavior during hyperparameter optimization. The framework holds the model, task, prompt structure, decoding settings, and optimization horizon fixed, while systematically varying what the agent can see. These context policies include access to task descriptions, evaluation metrics, parameter bounds, and different lengths of prior optimization history. This design makes it possible to separate the effect of informational exposure from the apparent capability of the agent itself.
The project evaluates these context policies across four machine learning benchmarks spanning regression, classification, materials science, geospatial data, housing prediction, and text toxicity classification. To avoid misleading results from lucky or unlucky starting points, the team first characterizes each benchmark landscape using Sobol sampling, then selects stratified initial configurations representing poor, neutral, and strong starting conditions. Performance is measured through normalized regret, allowing results to be compared across tasks with different metrics and optimization directions.
The findings show that initialization quality is one of the strongest drivers of agent performance. LLM agents tend to improve poor configurations quickly, but their gains plateau after the first few steps. When starting from already strong configurations, the agent often provides little benefit and can sometimes degrade performance. Context also matters, but not always in intuitive ways: explicit parameter bounds greatly reduce invalid proposals, yet do not necessarily improve final performance, while longer feedback histories can make the agent more conservative and less able to recover from poor starts.
From a research perspective, ContextEval reframes how LLM optimization agents should be evaluated. The results suggest that these agents currently behave less like systematic search algorithms and more like prior-driven corrective heuristics. They can recognize and repair obviously weak configurations, but they do not consistently perform robust iterative optimization, especially when compared with random search on more complex tasks. The broader contribution is methodological: ContextEval shows that context visibility should be reported and controlled in agent benchmarks, because differences in performance may reflect what an agent was allowed to see rather than how well it can reason.
Stay Connected
Follow our journey on Medium and LinkedIn.