Iterative Refinement of LLM-as-Judge Framework
Evaluating Context Strategies for LLM Agents
This project explored how large language models can be evaluated more reliably when they are used to summarize complex academic material. While LLMs can produce fluent summaries of lecture slides, assessing the quality of those summaries remains difficult. Traditional automatic metrics such as ROUGE, BLEU, and BERTScore are useful for comparison, but they often miss deeper qualities such as factual grounding, semantic completeness, domain relevance, and usefulness to human readers. The research focused on this gap by developing a scalable, reference-free evaluation framework for LLM-generated lecture summaries.
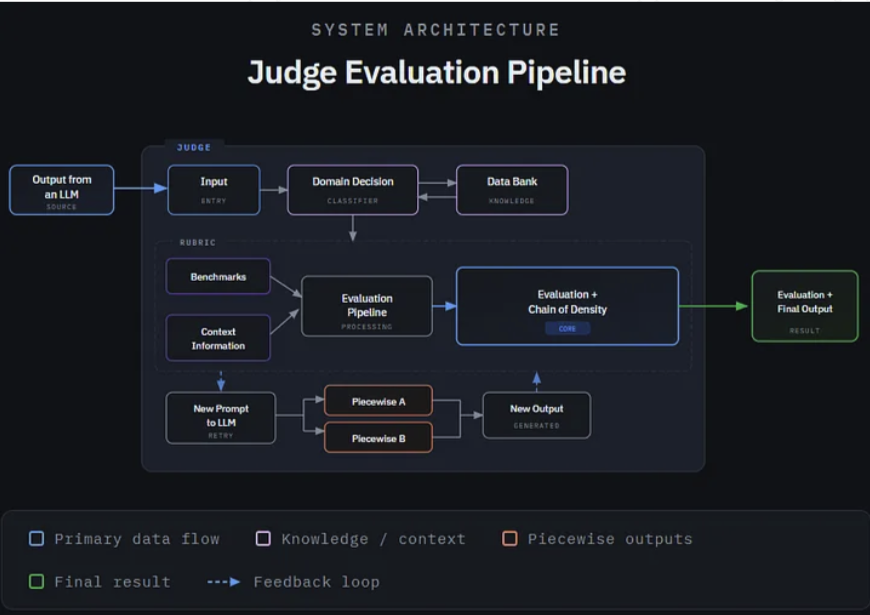
The team designed an iterative LLM-as-judge pipeline that combines rubric-based evaluation with deterministic quality signals. Instead of judging a summary once, the system evaluates the output across dimensions such as coverage, faithfulness, organization, clarity, and style, then uses that feedback to guide refinement over multiple rounds. The framework also incorporates domain-aware rubric routing, allowing evaluation criteria to adapt to the subject matter of the lecture rather than relying on a single generic scoring scheme. This makes the approach better suited for diverse academic content, where a strong summary may look different across engineering, natural sciences, humanities, social sciences, or business.
A key research contribution was the hybrid scoring method, which blends LLM judgment with measurable signals derived from the source slides. These signals include length error, section coverage, glossary recall, and suspected hallucination rate. By combining qualitative rubric scores with interpretable diagnostics, the system provides both an overall quality score and a clearer explanation of why a summary performed well or poorly. The project also introduced a trend-aware stopping controller and a best-of-last-k selection safeguard, helping the pipeline stop refinement once improvements plateau while reducing the risk that a weaker final rewrite becomes the reported output.
The experimental evaluation used seven UC San Diego lecture slide decks across multiple domains. Across these lectures, the pipeline produced consistently strong final summaries, with an average risk-adjusted score of 0.841. The results showed that most summaries reached strong candidate states within a small number of refinement rounds, with an average selected iteration of 3.4 and an average of 4.7 executed iterations. The findings also revealed important tradeoffs: rubric scores tended to cluster in the high range, while deterministic grounding signals provided more useful variation across lectures. This suggests that hybrid evaluation is more informative than relying on LLM judgment alone.
From a research perspective, the project demonstrates a practical path toward scalable evaluation of AI-generated educational content. It shows that LLM-as-judge systems can become more useful when paired with domain-aware rubrics, deterministic grounding checks, iterative feedback, and transparent logging. At the same time, the work highlights open challenges, including the need for larger datasets, stronger domain classification, improved hallucination detection, and validation against human judgments. As industry mentors, our role was to help guide the team toward a system that was not only technically rigorous, but also interpretable, reproducible, and relevant to real-world AI evaluation workflows.
Stay Connected
Follow our journey on Medium and LinkedIn.