Judging the Judges
Judging the Judges
Judging the Judges explores how large language models explain complex technical ideas, and how those explanations should be evaluated. While many AI benchmarks focus on whether a model gives the right answer, this project looks at a different question: does the model explain the answer in a way that people can actually understand?
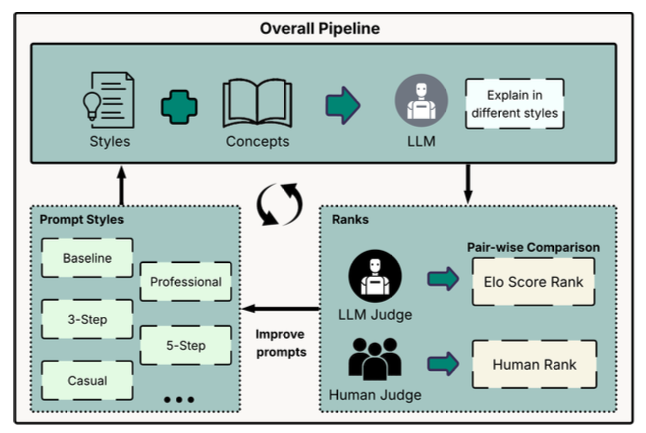
The project team designed a structured evaluation framework to test how prompt design affects explanation quality. Technical concepts from artificial intelligence, computer science, and statistics were selected, then an LLM was asked to explain each concept using different prompt styles, including baseline, casual, multi-aspect, step-by-step, and academic formats. The prompts were then refined through an iterative loop, making it possible to compare original prompts against improved versions.
To evaluate the explanations, the project used both automated and human judgment. In the LLM-as-Judge setting, a model compared pairs of explanations and selected which one was clearer, more helpful, and easier to understand. These pairwise comparisons were aggregated with Elo-style scoring to produce rankings across prompt styles. In parallel, human evaluators reviewed the same types of outputs, creating a way to compare model-based evaluation with actual human preferences.
The results showed that prompt structure has a measurable impact on explanation quality. Refined prompts generally performed better than their original versions, and conversational but structured prompts ranked highest across domains. Academic-style prompts consistently ranked lower, suggesting that formal language alone does not make an explanation more useful. The rankings were also relatively stable across AI, computer science, and statistics, which suggests that strong prompt patterns can generalize across technical subjects.
Most importantly, the project revealed that LLM judges and human judges do not always reward the same things. Human evaluators tended to prefer explanations that were longer, more organized, and easier to scan, while the LLM judge often favored shorter and more fluent responses. This gap shows why human-centered evaluation still matters. For teams building AI systems, the project offers a practical reminder: better AI explanations require not only better prompts, but also better ways to judge whether those explanations meet human needs.
Stay Connected
Follow our journey on Medium and LinkedIn.